
Introduction to AI-Feature Detection and Matching
Computer version
Feature Detection and Matching
我们讲解这个Feature Detection and Matching概念的之前可以先介绍一下Computer version。
视觉传感器
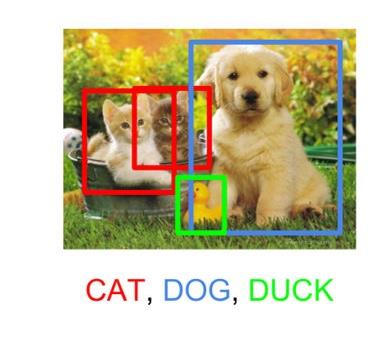
视觉传感器是能够捕获视觉数据的设备,用于帮助人工智能系统观察并理解周围环境。视觉传感器会生成丰富的视觉观测数据,供AI进行分析,最终帮助其做出决策。AI在使用视觉传感器时,通常需要关注以下几个关键过程:

-
特征检测 (Feature Detection):
- 特征检测是从传感器观察中提取关键信息的过程,比如检测图像中的边缘、角点或斑块。
- 这些特征可以用作后续识别和匹配的基础,帮助系统识别环境中的对象和场景。
-
识别 (Recognition):
- 识别是给检测到的图像特征贴上标签的过程,使系统能够区分不同的对象,比如猫、狗、建筑物等。
- 这个过程可以帮助AI识别物体的类别和属性,从而做出更准确的决策。
-
重建 (Reconstruction):
- 重建是利用图像信息创建环境几何模型的过程,比如构建3D模型或深度图。
- 这一过程在无人驾驶、机器人导航等领域尤为重要,因为它能帮助AI了解空间中的障碍物和路径。
可以把视觉传感器想象成一个人的眼睛。眼睛看到的景象通过大脑处理后,我们可以识别出身边的物体(识别),分辨出重要的特征(特征检测),并形成周围环境的3D模型(重建)。
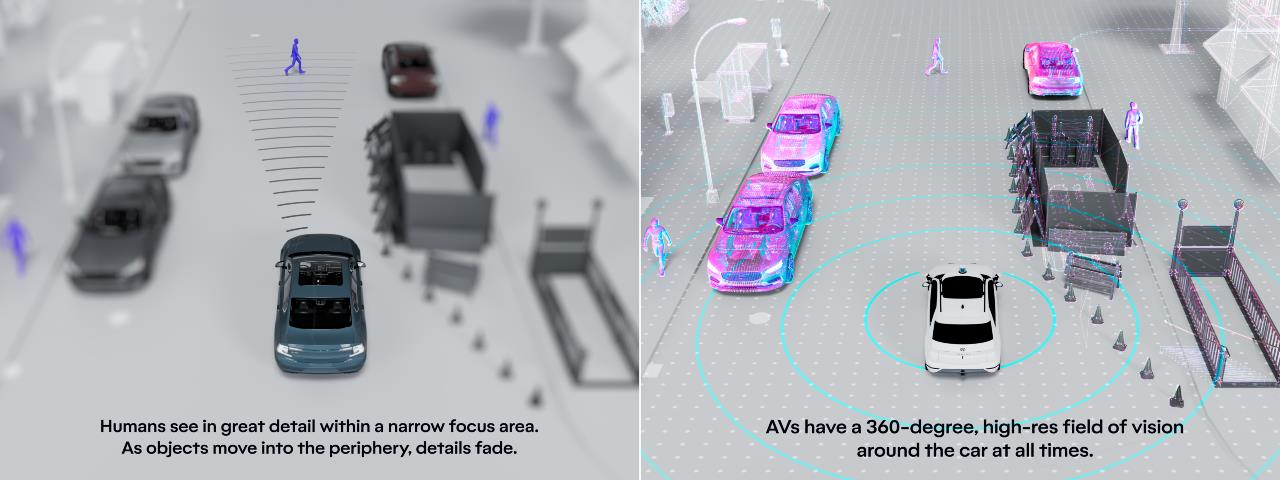
图像形成 (Image Formation)
图像形成是视觉传感器如何感知并构建场景的过程。这里给出了两种视觉体验的对比:
-
人类视野:
- 人类的视觉系统在一个狭窄的焦点区域内可以看到非常清晰的细节,而周围的视野会逐渐模糊。
- 这意味着我们专注的区域清晰,而远处或边缘的细节较少。
-
自动驾驶车辆的视野:
- 自动驾驶车辆通常配备360度的视觉传感器,它们可以实时监控车辆周围的环境。
- 这种高分辨率的全景视野能让AI感知四周的每个角落,确保安全导航。
人类视觉可以理解为在一个小聚光灯下观察世界,而自动驾驶车辆则像被一个360度的探照灯包围,能够看到周围的一切。通过视觉传感器和图像形成,AI能够理解和重建环境,从而帮助它做出合适的行动决策。这些技术在自动驾驶、安防监控和机器人导航等领域应用广泛。
这主要涉及到光的传播和成像的原理:
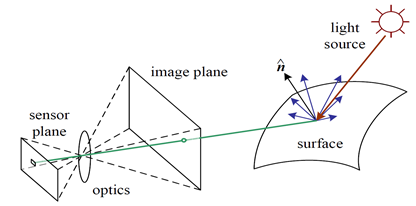
- 光源发射光线 ,这些光线照射到物体表面,并发生反射。
- 部分光线被镜头(optics) 收集 ,并通过镜头折射到传感器上。
- 图像平面上的点就是物体在成像设备中的投影,这些投影构成了最终的图像。
像我们用相机拍摄照片。光源(比如太阳)照射到物体上,物体反射光线,光线通过相机镜头,最终在相机的传感器上形成图像。
图像的基本概念 (Images Basics)
在图像处理和计算机视觉中,图像通常由 像素 (pixel) 构成。像素是图像的基本单位,每个像素存储了该位置的颜色或亮度信息。
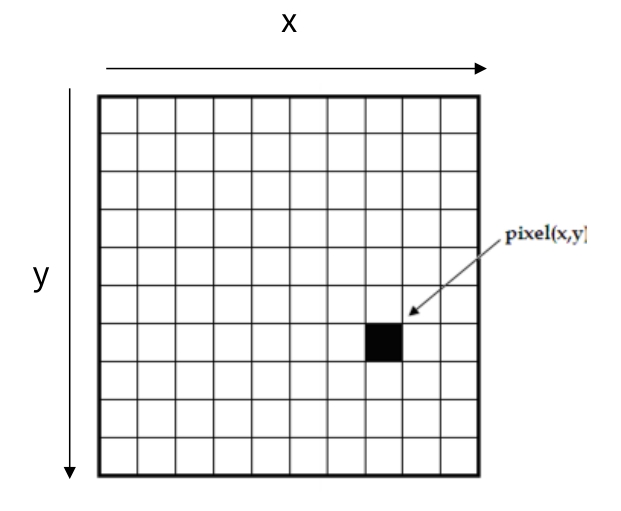
像素坐标
- 每个像素都有一个坐标 (x, y),通常从图像的左上角开始,向右是 x 轴,向下是 y 轴。
像素值
像素值决定了图像中的颜色或亮度,可以分为以下几种类型:
- 二值图像(Binary Image) :每个像素只有黑 (0) 或白 (1)。

- 灰度图像 (Grayscale Image) :每个像素用一个 0 到 255 的数值表示亮度,0 表示黑色,255 表示白色。

- 彩色图像 (Color Image) :每个像素包含 RGB(红、绿、蓝)三种颜色分量,每个分量的值在 0 到 255 之间,组合后可以表示各种颜色。

Depth Images (深度图像)
Depth Images提供了关于图像中每个像素距离的信息,即沿 z 轴的深度信息。

像素值
- 在深度图像中,每个像素值表示物体距离传感器的距离。
- 较小的值表示物体较近,而较大的值表示物体较远。
RGB-D 图像
- RGB-D 图像是将 颜色图像(RGB) 和 深度图像 (Depth) 结合在一起,形成的复合图像。
- 在实际应用中,这样的图像不仅能提供物体的颜色信息,还能提供物体的距离信息,使得图像更加立体。
应用场景
- 机器人视觉:深度信息帮助机器人理解周围物体的距离,以避免障碍物或进行物体抓取。
- 增强现实 (AR):通过深度图像,AR设备可以更准确地把虚拟物体放置在真实场景中。
- 3D建模:深度图像常用于构建物体或环境的3D模型。
了解完之后咱们进入正题
🔐 outline
Types of features: keypoint, edges and etc.
Feature detection: e.g. FAST algorithm
Feature description: e.g. SIFT algorithm
Feature matching and tracking techniques
什么是特征检测与匹配 (Feature Detection and Matching)?
在计算机视觉中,特征检测与匹配是用于将两张或多张照片“对齐”的技术。你可以把它想象成拼图游戏,在拼图中,我们通过形状或颜色找到匹配的部分,将它们拼接在一起。计算机视觉的原理类似,我们在不同的照片中找到“特征点”,也就是照片中特殊的部分,然后通过这些特征点将图像对齐,形成一个无缝的全景。
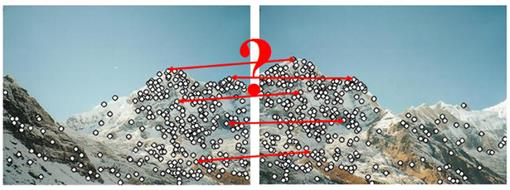
例子1:拼接重叠的照片


这两张图展示了如何将两张重叠的照片对齐成全景。照片中重叠的部分包含了相同的山峰,计算机会识别出这些共同的特征点(如山峰的形状、纹理等),然后将两张照片拼接在一起。这个过程可以用特征检测算法实现,比如 SIFT(Scale-Invariant Feature Transform)或 ORB(Oriented FAST and Rotated BRIEF)。这些算法帮助计算机在不同的角度、距离下,仍然可以识别出相似的特征点。
例子2:生成3D模型或中间视图

这两张照片展示的是一个小屋从不同角度拍摄的图像。我们可以通过匹配这些照片的特征点,来生成一个3D模型。这种技术应用于生成虚拟现实场景、3D建模等应用中。
特征类型 (Types of Features)
在计算机视觉中,图像的“特征”就是帮助计算机识别图像中的重要信息的点或线。我们可以将特征分为以下几种类型:
- 关键点 (Key points):也叫做“interest point”,是图像中某些具有独特特征的小块区域。比如说照片中某个窗户的角落、山的顶峰等。关键点通常用于识别不同照片中相同的区域。

- 边缘 (Edges):边缘定义了图像中的边界,比如一幢建筑的轮廓或树叶的轮廓。边缘特征通常具有方向性,可以是曲线或直线段。它们可以帮助计算机理解图像中的物体轮廓和形状。


关键点 (Key points) 的用途
关键点通常用于将不同图像中的相同区域进行匹配或跟踪。计算机可以在一张图像中找到一个关键点,然后尝试在另一张图像中找到相似的点,借此来确定两张图像的对应关系。
匹配与跟踪定义
- 匹配(Matching) :独立地在每张图像中寻找特征,然后将它们配对。就像是找到两个拼图中相同形状的碎片。
- 跟踪(Tracking) :找到某个图像中的关键点后,跟踪它在其他图像中的位置变化。可以想象成,你找到了一只蜜蜂,并追踪它在花园中的飞行路径。
关键点检测与匹配的步骤 (Stages of Keypoint Detection and Matching)

- 特征检测 (Feature Detection):在图像中找到潜在的关键点。
- 特征描述 (Feature Description):计算机会对这些关键点周围的像素区域进行编码,从而创建一个紧凑的描述。这样可以更高效地比较和匹配不同图像中的特征。
- 特征匹配 (Feature-Based Correspondence):
- 特征匹配 (Feature Matching):在多张图像中找到可能的匹配特征点。
- 特征跟踪 (Feature Tracking):在后续图像中仅搜索附近区域,从而高效地跟踪每个检测到的特征。
特征检测 (Feature Detection)
特征检测是找到图像中key points。常见的特征类型有两种:角点 (Corner) 和 斑块 (Blob)。
- 角点 (Corner):角点是图像中两条或多条边交汇的地方。比如建筑物的窗户角、书的边角等。角点在图像中的位置是非常明确的,通常能很好地帮助我们进行图像的对齐或匹配。
- 斑块 (Blob):斑块是指图像中与周围区域不同的图案,通常在颜色或亮度上有显著的变化。比如墙上的光斑或某个物体的阴影区域。斑块可以帮助我们识别图像中的特定区域。
你可以想象角点就像一个房间的墙角,它的具体位置很容易确定。而斑块则更像是墙面上的一个不同颜色的油漆斑,可以帮助你标记出墙面上“不同”的区域。
FAST 特征检测方法 (FAST Feature Detection)
FAST (Features from Accelerated Segment Test) 是一种快速检测角点的算法。它的主要思路是通过检查一个像素点 的周围像素的亮度是否不同,来判断该点是否为角点。具体步骤如下:

- 选择一个像素:这个像素就是我们要测试的点,看看它是否可能是角点。
- 选择阈值 :阈值用于控制亮度差异的灵敏度。假设 表示像素 的亮度,那么如果周围像素的亮度比 高出或低于 ,则认为存在亮度差异。
- 环绕 的 16 个像素:我们在像素 周围选择一圈共 16 个像素,并检查这些像素的亮度。
- 判断是否为角点:如果在 周围的 16 个像素中,有 12 个连续的像素亮度都比 更亮,或者都比 更暗,那么 就可以被认为是一个角点。
- 为了使算法快速,首先将圆的像素 1、5、9 和 13 的强度与进行比较。从上图可以明显看出,这四个像素中至少有三个应该满足阈值标准,这样兴趣点才会存在。
- 如果四个像素值( I1、I5、I9、I13)中至少有三个不高于或低于,则p不是interest point(角点)。在这种情况下,拒绝像素p作为可能的兴趣点。否则,如果至少有三个像素高于或低于,则检查所有 16 个像素,并检查 12 个连续像素是否符合标准。
- 对图像中的所有像素重复该过程。
你可以想象在夜空中看到一颗特别明亮的星星,星星周围的其他星光较暗,这就让这颗星星显得特别突出。类似地,FAST 方法通过寻找亮度差异显著的点来确定角点。
FAST 算法的优点是速度快,特别适合实时计算机视觉应用,比如视频帧中的特征检测。因为它只需要检查固定数量的像素,而不是对每个像素都进行复杂的运算,所以非常高效。
角点检测器 vs. 斑块检测器
在计算机视觉中,不同的检测器用于识别图像中的特征。角点和斑块是最常用的两种特征类型,每种类型的检测器有不同的优缺点:
-
角点检测器 (Corner Detectors):
- ✔ 计算速度快:角点检测器的算法简单,比如 Harris 角点检测和 FAST 检测器。它们通过检测图像中亮度急剧变化的区域来识别角点,因此速度很快。
- ✖ 特征不够明显:角点通常比斑块少一些独特性(distinctiveness),因为角点可能在图像的某些角度或尺度变化时不易重新识别。
- ✖ 不适应大尺度变化:当图像发生大幅缩放或视角改变时,角点较难重新检测。
- 例子:Harris 角点检测器、FAST 检测器。
-
斑块检测器 (Blob Detectors):
- ✔特征更加明显:斑块能在图像中产生更为独特的特征,更加便于检测和匹配。
- ✔适应大尺度变化:斑块能在不同的视角和尺度下更加稳定地被检测到,因此适合做更复杂的特征匹配。
- ✖ 计算速度较慢:斑块检测器通常更复杂,计算时间比角点检测器长。
- 例子:SIFT (Scale Invariant Feature Transform),SURF (Speeded Up Robust Features)。
你可以把角点检测器想象成是在一张图片里快速寻找边缘的“急性子”朋友,而斑块检测器则像是花更多时间去分析图片中独特部分的“细心”朋友。当你需要快速检测图像中的特征时,可以选择角点检测器;而当你需要在不同视角或缩放中稳定的特征时,斑块检测器就更合适。
特征描述 (Feature Description)
特征检测完成后,下一步是将每个特征点周围的区域转换为一个紧凑的“描述符 (descriptor)”,这样计算机可以通过这些描述符来进行匹配。描述符本质上就是对特征周围区域的编码,使得它们在不同图像中可以找到相似的特征点。
Simplest descriptors(描述符):
- Simplest descriptors可以基于特征点周围区域的像素亮度值。例如,通过计算像素强度的总和或差异,可以生成描述符。
- 比较描述符时,可以使用“均方误差 (Sum of Squared Differences, SSD)”或“归一化交叉相关 (Normalized Cross Correlation, NCC)”等误差度量方法。
- 缺点:Simplest descriptors对图像的缩放和旋转不具备不变性,也就是说当图像被缩小或旋转时,这些描述符可能会失效。
🌠可以把描述符想象成一个人的“指纹”。简单的描述符可能就像是只记录指纹的整体形状,虽然简单但不够精确。而更复杂的描述符则会详细记录指纹的每条细纹,这样即使手指角度稍有不同,指纹也能被识别出来。
SIFT 描述符 (SIFT Descriptor)
SIFT(Scale Invariant Feature Transform)是一种强大的特征检测和描述方法,能够在图像缩放、旋转等变化下保持特征的稳定性。它的核心思想是计算出特征点周围的梯度信息,并用一个向量来描述它,这样在不同的图像中也能找到相似的特征点。我们可以分以下步骤来理解 SIFT 描述符的构造:

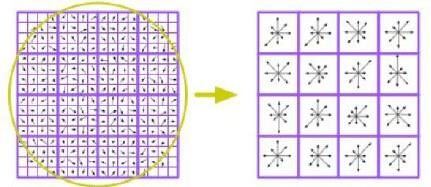
- 选择 16x16 像素区域:在检测到的特征点周围取一个 16x16 的像素块,作为分析的区域。
- 计算梯度方向和幅值:在每个像素点上计算图像亮度的梯度(即亮度变化的方向和大小)。梯度表示了像素强度的变化情况,比如从暗到亮的方向。
- 划分子区域:将 16x16 的区域分为 4x4 的子区域,每个子区域包含 4x4=16 个像素。
- 计算直方图:对每个子区域的梯度方向进行统计,生成一个 8-bin 的方向直方图(即将方向分成 8 个不同的区间来统计)。这会得到 4x4 个子区域的方向信息。
最终,SIFT 描述符是一个 128 维的向量(16 个子区域,每个区域有 8 个方向值)。这个向量编码了特征点周围的纹理信息,使得在不同图像中可以通过比较这个向量来找到匹配的特征点。
🎌可以将 SIFT 描述符想象成一本书的“内容摘要”。这本书的内容很多(像素信息),但我们通过分析各个部分的重要内容,生成了一个简明的摘要(128 维向量),这样即使换一本不同版本的书(图像变形),我们仍然能通过摘要来辨认出它是同一本书。
SIFT的优点:
- 局部性: 特征是局部的,因此对遮挡和混乱具有很强的鲁棒性(没有事先进行分割)
- 独特性: 单个特征可以与大型对象数据库相匹配
- 数量: 即使是很小的物体也可以生成许多特征
- 效率: 接近实时性能
- 可扩展性: 可以轻松扩展到各种不同的特征类型,并且每种类型都增强了稳健性
特征匹配 (Feature Matching)
在检测到并描述了特征后,接下来要做的就是将不同图像中的特征进行匹配。特征匹配的目的是找到同一个物体在不同图像中的位置。常见的匹配方法包括:
- 欧几里得距离 (Euclidean Distance):计算描述符之间的距离,距离越短,说明两个描述符越相似。可以设定一个距离阈值来过滤掉不匹配的特征。
- 最近邻匹配 (Nearest Neighbour):在一张图像中找到与另一张图像中的特征描述符最近的点。这种方法速度快,但可能会产生误匹配。
- 最近邻距离比 (NNDR) 匹配:这是 SIFT 常用的匹配方法,通过计算最近邻距离和次近邻距离的比值来判别是否为有效匹配。当比值低于一定阈值时,认为是正确匹配。NNDR 通过与次近邻比较来避免误匹配。
🎨可以将特征匹配想象成在两副拼图中寻找相同的拼块。欧几里得距离相当于测量两块拼图碎片的相似度,最近邻匹配就是选择最相似的拼块,而最近邻距离比匹配则更精细地比较最相似和次相似的拼块,以确保匹配的准确性。
Feature Matching: Euclidean Distance
假设我们有两个点 和 ,它们在二维平面上的坐标分别为 和 。欧几里得距离 可以用以下公式计算:
这个公式可以推广到更高维度,例如在描述符是一个多维向量的情况下。如果描述符向量是 和,那么它们之间的距离为:
距离越小,表示这两个描述符越相似;相反,距离越大,则相似性越低。因此,我们可以使用欧几里得距离来衡量描述符的非相似度,从而用于特征匹配。
例子
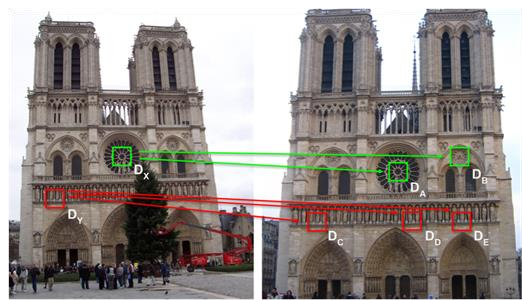
左图和右图分别包含两组特征点,计算欧几里得距离后,我们可以找到匹配的特征点。例如:
- 点 与点 的距离是 85,而与点 的距离是 95。因此 与 更相似。
- 点 与点 、、 的距离分别为 80、75 和 77。由于距离最短的是,所以 与 是匹配点。
这种方法可以通过比较描述符之间的欧几里得距离来找到不同图像中相似的特征点。
📋可以把这个过程想象成在地图上找最近的地标。如果你站在某个位置 (例如特征点),想找一个最近的咖啡馆(匹配的特征点),你会测量各个咖啡馆的距离,选择最近的一个。同理,在特征匹配中,计算机选择与特征描述符距离最短的点作为匹配点。
Feature Matching: Distance Thresholding
在特征匹配中,距离阈值是用来筛选“可能是匹配点”的方法。我们通常会设定一个最大允许距离(阈值),如果两个特征点之间的距离小于该阈值,就认为它们是匹配的特征点。这样可以排除一些不准确的匹配,从而提高匹配的质量。
结果评价指标
为了评估特征匹配的效果,我们可以使用以下四个评价指标:
- True Positive (TP):正确匹配。真实匹配的点被系统正确识别为匹配。
- False Positive (FP):错误匹配。系统错误地将一些非匹配点识别为匹配点。
- False Negative (FN):漏检匹配。系统未能识别出真实匹配的点。
- True Negative (TN):正确排除。不匹配的点被系统正确地识别为非匹配点。
🐇可以把这四个指标想象成找对和错的人。如果你的任务是找到你的朋友:
- TP:你找到了真正的朋友。
- FP:你认错了人,把陌生人误认为朋友。
- FN:你的朋友在那里,但你没认出来。
- TN:你没有认错人,排除了所有陌生人。
例子
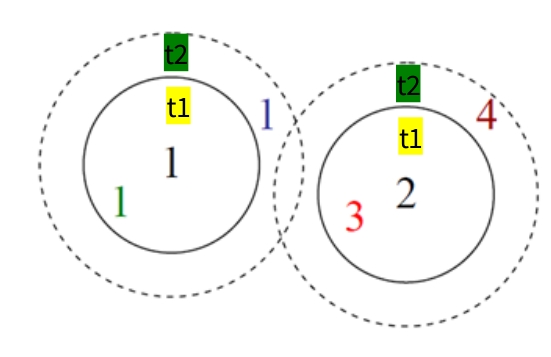
在这张图中两个特征点 ( t1 ) 和 ( t2 ) 是设定的距离阈值范围:
| t1 | t2 | |
|---|---|---|
| True positives (TP) | 1 | 1,1 |
| False positives (FP) | 3 | 3,4 |
| False negatives (FN) | 1 |
- TP (True Positive):在 阈值下,找到真实匹配点 。
- FP (False Positive):在 阈值下,误认为点是匹配的。
- FN (False Negative):在 阈值下,漏掉了点 的一个匹配。
- 类似地,使用 阈值时可以计算出对应的 TP、FP 和 FN。
通过这些评价指标,我们可以分析距离阈值是否设置得合理。理想情况下,我们希望有更多的 TP、尽可能少的 FP 和 FN,以保证匹配结果的准确性。
Feature Matching: Experimenting with the Threshold
混淆矩阵 (Confusion Matrix)
混淆矩阵的行表示预测的匹配结果,列表示真实的匹配情况:
| 真匹配 (True Matches) | 真非匹配 (True Non-matches) | |
|---|---|---|
| 预测匹配 (Predicted Matches) | 18 (TP) | 4 (FP) |
| 预测非匹配 (Predicted Non-matches) | 2 (FN) | 76 (TN) |
评价指标
-
精度 (Precision):精度表示所有预测为匹配的点中,实际是匹配的比例。公式如下:
精度为 0.82 表示所有预测为匹配的点中,82% 是正确的匹配。
-
召回率 (Recall):召回率表示所有真实匹配点中,成功被识别为匹配的比例。公式如下:
召回率为 0.90 表示真实匹配点中,有 90% 被正确识别出来。
-
正预测值 (Positive Predictive Value, PPV):正预测值在这里等同于精度,值为 0.82。
🐋解释
- 精度较高表示预测为匹配的点大多是正确的,但也可能遗漏一些匹配点。
- 召回率较高表示大多数真实匹配点被正确识别出来,但可能会有一些误匹配。
- 当我们调整距离阈值时,精度和召回率可能会发生变化。通常需要在精度和召回率之间找到一个平衡,以获得更好的匹配效果。
Feature Matching: Nearest Neighbour (NN)
在特征匹配中,最近邻匹配是一种简单的方法,即找到距离目标特征描述符最近的另一个特征描述符,称为“最近邻 (Nearest Neighbour)”。然而,仅选择最近邻匹配可能会导致误匹配,因此我们引入 最近邻距离比 (NNDR),它能进一步提高匹配的可靠性。
-
NNDR的定义:计算两个最相似的描述符的距离之比,公式为:
其中, 是目标描述符和最近邻描述符的距离, 是目标描述符和次最近邻描述符的距离。
-
NNDR的意义:一个低比值( 较小)表示目标描述符与最近邻的相似度远高于次最近邻,是一个好的匹配;相反,一个高比值则表明匹配不确定性较大,可能是错误匹配。因此,NNDR 通过比较最近邻和次最近邻的距离来减少误匹配。
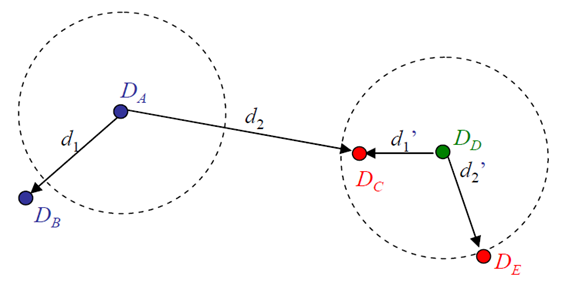
可以将 NNDR 想象成在选择好友时,不仅考虑最亲密的朋友,还要看与其他朋友的关系差距。如果你和某个朋友的关系明显比其他人都要亲近,那你们的关系就是非常牢固的(匹配可靠);如果你和几个朋友的亲近程度差不多,那选择就不那么确定了(匹配有歧义)。
特征跟踪 (Feature Tracking)
特征跟踪用于在视频或多帧图像中跟踪特定的特征点,主要关注特征在连续帧中的运动。特征跟踪通常只在特征周围的小区域内搜索,从而减少计算量。
-
误差度量:
- 均方差 (Sum of Squared Differences, SSD):计算两个区域像素值的平方差,SSD 越小表示两个区域越相似。
- 归一化交叉相关 (Normalized Cross Correlation, NCC):计算两个区域之间的相似性,NCC 值越大表示相似性越高。
-
仿射运动模型 (Affine Motion Models):使用仿射变换来模拟特征点在不同帧之间的运动。仿射变换可以包括平移、旋转、缩放等操作,使得特征跟踪更具鲁棒性。常用的算法包括 Kanade-Lucas-Tomasi (KLT) 跟踪器。
 wechat
wechat alipay
alipay






