
Introduction to AI-Visual Odometry
Computer Vision
Visual Odometry
什么是Visual Odometry
Visual Odometry (VO) (视觉里程计)是一种技术,通过摄像头捕捉的图像来推测机器人的位置和方向。这个过程有点像我们走路时观察周围的物体来判断自己在移动的方向和距离。
为什么要用Visual Odometry?
在自动导航中,我们希望机器人能知道自己在环境中的位置和方向。比如一辆自动驾驶汽车需要实时了解自己在马路上的位置,以避免偏离车道或撞上其他车辆。
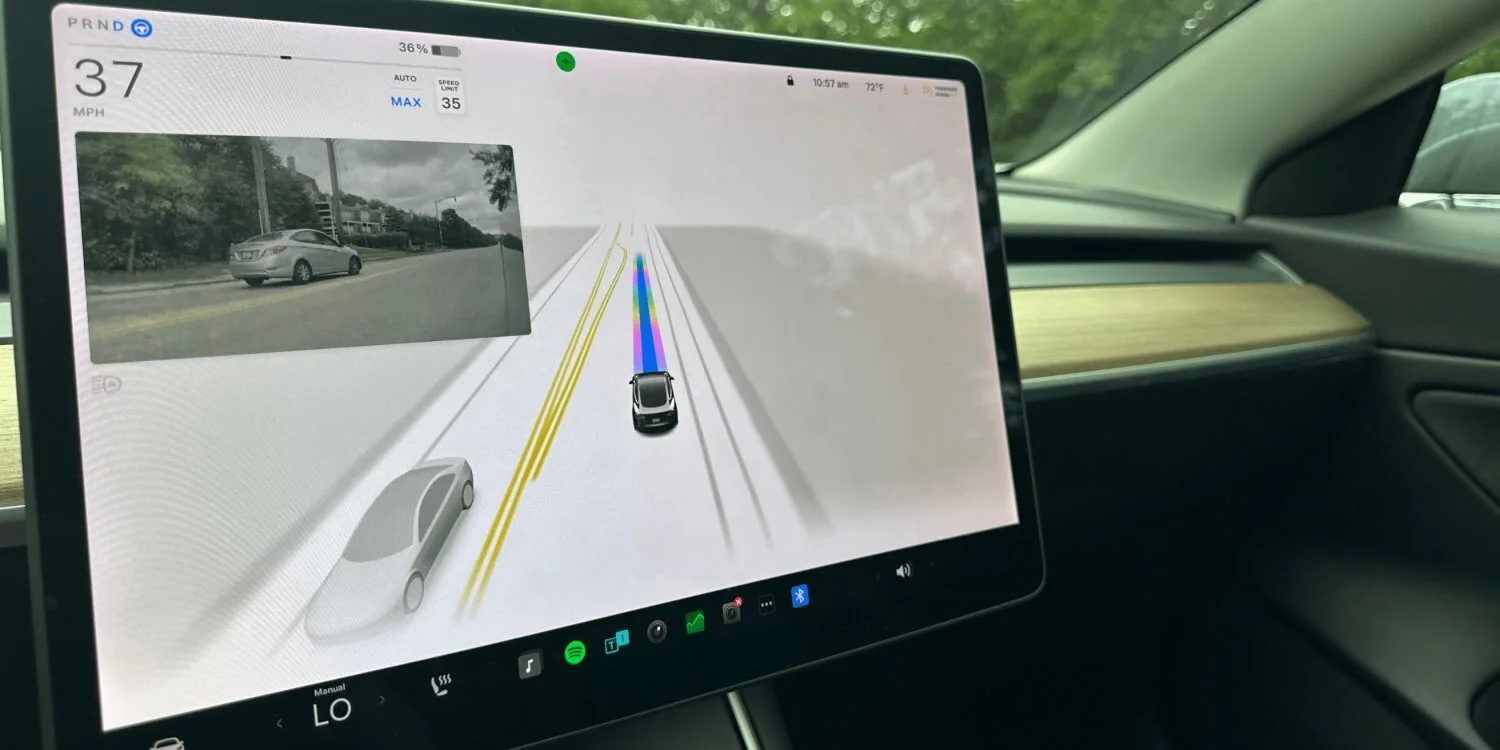
Wheel Odometry 是通过轮子的转动来估算位置。
然而,Wheel Odometry 有很多限制,比如它容易受到地形影响(泥泞地面、打滑的地方)。
而 Visual Odometry 则利用摄像头的视觉信息,能够在这些不平稳的环境下更精确地估算位置。
Visual Odometry的工作原理
VO 通常通过以下几个步骤完成:
- 捕捉图像:摄像头捕捉到连续的图像帧。
- 特征点检测:算法会在图像中寻找一些独特的特征点,比如墙上的角、地上的石子等。可以想象,这些特征点就像你在公园散步时,用一些有特征的建筑物来确定位置。
- 跟踪特征点:VO 会在不同帧中跟踪这些特征点,看它们在图像中的位置如何移动。
- 估算运动:通过这些特征点的移动方向和距离,VO 可以估算出摄像头(也就是机器人)的移动路径。
假设你在一个漆黑的房间里,只能通过手电筒的光线观察到周围的墙和物体。每次你走一步,你会看到墙上的一些标志物,比如窗户、门把手等,这些标志物的相对位置会随着你移动而发生变化。根据这些变化,你就能推测自己向哪个方向移动了多远。
挑战
- 误差累积:每次估算都有一些小误差,这些误差会随着时间累计起来,使得位置估算越来越不准确。
- 光照变化:不同光照条件下,图像的特征点可能会发生变化,这会影响到 VO 的准确性。
- 快速运动和模糊:当摄像头移动太快时,图像可能会模糊,从而让特征点的检测和跟踪变得困难。
Problem Formulation
这里的 Problem Formulation 其实是给 Visual Odometry (VO) 提供一个数学描述。假设一个机器人(或者“agent”)在环境中移动,并使用一个固定在其上的相机系统来拍摄图像。我们会在不同的时间点 捕捉这些图像。
Set of image
-
单目系统 (Monocular):即单个摄像头(“单眼”)。图像集合表示为 ,这里的 到 是从起始到当前时间点拍摄的一系列图像。
-
双目系统 (Stereo):即双摄像头(“双眼”),分别用左摄像头和右摄像头来拍摄。左摄像头的图像表示为 ,右摄像头的图像表示为 。
通过捕捉一系列图像(单目或双目),VO 算法可以分析这些图像之间的差异来估算机器人在环境中的位置和移动情况。
假设你在旅游时,每隔几分钟拍一张照片。通过比较这些照片中地标的相对位置变化,你可以推测出自己是往哪个方向走,走了多远。同样,VO 会通过分析这些不同时间点的图像,来确定机器人的移动轨迹。
接下来我们要理解如何表示相机在不同时刻的位置。
那么这里用到rigid body transformation(刚体坐标变换矩阵)
刚体坐标变换矩阵 $T_{k, k-1}$
为了描述相机在相邻两个时刻 和 的位置变化,我们使用如下的变换矩阵:
- 是旋转矩阵,表示相机在这段时间内发生的旋转。可以把它想象成相机方向的变化。
- 是平移向量,表示相机在这段时间内的位置移动,类似于相机在空间中“走”了多远、多高。
这个矩阵可以描述相机的位姿(位置和方向)在时间 到 之间的变化。
❤️想象你在房间里拿着相机拍照。当你从一个位置移动到另一个位置时,不仅改变了你站的位置(平移),也可能转动了身体方向(旋转)。这个变换矩阵 就是用来记录这种“走了多远、转了多少度”的信息。
然后我们通过多个变换累积出当前相机的位置和姿态(pose)。
变换集
我们有一系列的变换,表示相机在不同时间点的运动(或变换)。每一个 $T_k $都描述了相机从一个时刻到下一个时刻的位姿变化。
相机姿态集
相机在不同时间点的姿态(位置和方向)用 来表示。这里的 是初始位置,而 是在时间 时刻的姿态。
姿态的计算
每一个新的相机姿态 是由前一个姿态 经过一个变换 得到的。用数学式表示就是:
这个公式的意思是:当前的姿态 是通过把前一个姿态 与当前的变换 组合起来得到的。
累积过程
随着相机的移动,我们会不断累积这些变换,逐步计算出从起始位置 到任意时刻 的位置和方向。
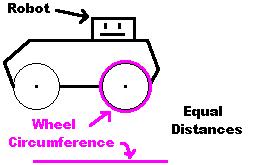
现在,我们来看 Visual Odometry (VO) 的主要任务和计算方法。
Main Tasks of VO
-
计算每个变换 ,即从时间 到的位置变化。
-
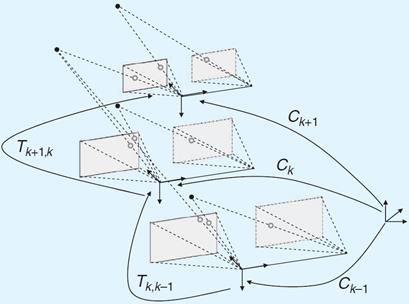
这个变换 是基于图像对 和 计算出来的。通过比较这两幅图像中的特征点(比如图中的红点和蓝点),VO 算法可以推测出相机在空间中移动的方向和距离。
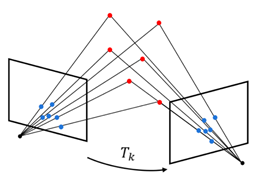
-
当我们计算出一系列变换 后,就可以通过将它们累积起来,得到完整的相机轨迹 。
-
简单来说,VO 会逐步将每个变换叠加,以追踪相机从起点到当前的完整路径。
VO 是逐步恢复路径的过程,称为“增量式”计算。每当获得新的图像对,VO 就会计算新的变换并更新相机的位置。这种方式让 VO 可以实时地跟踪相机的运动路径。如下图:
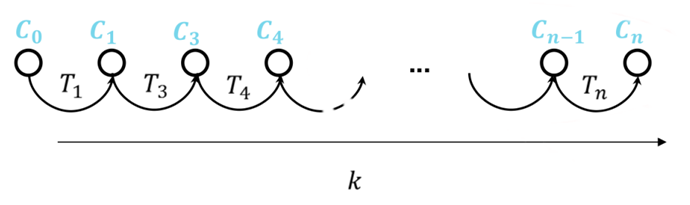
想象你在走迷宫,每走一步都会记录当前的转弯方向和步数。这些记录相当于每一个。当你一步步地记录下来后,就能在纸上画出完整的路径,这就像累积 得到相机的轨迹。
VO计算流程图

在这张图中,可以发现:
-
首先,我们会获取一系列连续的图像,通常是视频帧。每一帧图像都包含了一些环境信息,这些图像将用于估算相机的运动。
-
接下来要在每一帧图像中,我们需要找到一些“特征点”,比如角点或边缘。可以把这些特征点想象成图像中的显著标志,就像你走在街上会注意到一些显眼的建筑。
-
接下来是对特征的匹配和跟踪
- 匹配(Matching):对每一帧中检测到的特征点,尝试在相邻帧中找到相似的特征点。匹配的依据是相似度度量(例如颜色、形状)。
- 跟踪(Tracking):如果在某一帧中找到了一个特征点,我们希望在接下来的几帧中跟踪它的移动。这通常通过局部搜索(如相关性计算)来实现,以确保我们在运动中准确跟踪到相同的特征点。
-
在特征匹配或跟踪完成后,我们可以通过分析这些特征点在相邻帧之间的移动来估算相机的运动。
VO 可以根据不同的传感器数据格式,采用不同的运动估算方法:2D到2D:当两个帧 和 都以2D图像坐标表示时,我们会使用2D到2D的运动估算。这种方法依赖于图像平面上特征点的匹配。
3D到3D:当我们有3D点(即在三维空间中测量的点,如深度数据),则使用3D到3D的运动估算。这种方法可以直接在空间中估算相机的平移和旋转。
3D到2D:在这种方法中,我们有一组3D点(从上一帧获取)和它们在当前帧的2D投影。这种组合允许我们推断相机的姿态变化。
2D到2D运动估算的详细步骤以 2D到2D的情况为例,我们的流程如下:
捕捉新帧 。
提取并匹配特征点:在帧 和 之间找到相似的特征点。
计算本质矩阵(Essential Matrix):本质矩阵包含了图像对 和 之间的几何关系,可以从特征点的对应关系中计算。
分解本质矩阵:将本质矩阵分解为旋转矩阵 和平移向量 ,从而形成变换矩阵 $T_k $。
计算相对尺度并重新调整 的尺度。
拼接变换:通过累积变换,得到当前相机姿态。
重复以上步骤以获得持续的轨迹。
以下为流程图
估计方法 单目VO 双目VO 2D-2D ✔ ✔ 3D-3D ✔ 3D-2D ✔ ✔ -
最后在获得初步的运动估计后,我们会使用 束调整(Bundle Adjustment) 这样的优化技术,对所有特征点和位置进行微调,以得到更准确的相机运动估算。这个步骤包括为:
- 对最后的m帧进行优化,以获得更准确的局部轨迹估计。
- 减少 漂移(drift),即随着时间推移积累的误差。
🔎可以将整个过程想象成一个侦探追踪物体的移动:
- 侦探获得了连续的照片(图像序列)。
- 在每张照片中,他找到了几个重要的标记(特征点)。
- 他将这些标记在每张照片中进行比对和跟踪,确保找到相同的标记。
- 最后,他根据这些标记的移动估算出物体的路径,并通过细致分析进一步调整,以得到更精确的结果。
最后讲解一下什么是drift(漂移)
Drift
在 Visual Odometry (VO) 中,漂移(Drift) 是一个重要问题。漂移是指估算出的轨迹和真实轨迹之间的差异。
漂移的原因
漂移主要是由于在计算每对帧之间的运动时引入的误差累积而成的。随着时间推移,这些小误差逐渐积累,导致估算的路径与实际路径出现显著的偏差。
漂移中的不确定性
在相机姿态 处的误差或不确定性来源于两个方面:
- 在前一个姿态 的不确定性:由于前一帧的误差会传递到当前帧。
- 当前变换 的不确定性:当前帧到下一帧的位姿变化也可能有误差,这会进一步加剧漂移。
可以把漂移想象成你在绘制地图时,每一步都稍微偏离了一点。当你走得越远,这些小偏差累计起来,就会导致最终的地图与真实路径有很大出入。
为了解决漂移问题,VO 通常会结合其他技术,如 束调整(Bundle Adjustment) 和 全局定位,以减少累积误差,从而提高轨迹的准确性。

SLAM 和 VO的区别
SLAM(Simultaneous Localization and Mapping)
SLAM 是 同时定位与地图构建,用于跟踪机器人在环境中的位置,同时构建环境的地图。
- 地图构建:SLAM 不仅仅追踪机器人轨迹,还会持续更新环境的地图。
- 目标:SLAM 的目标是获得一个 全局一致 的轨迹和地图,这意味着整个路径和地图在全局范围内是准确的。
- 闭环检测(Loop Closure):SLAM 会检测机器人是否回到一个已经访问过的位置,如果检测到,就可以利用已知位置来纠正漂移误差,从而减少轨迹估算的误差。
VO(Visual Odometry)
VO 是 视觉里程计,主要用于增量式地复原相机的轨迹。
- 局部一致性:VO 的目标是获得一个 局部一致 的轨迹,它注重的是相邻位置之间的准确性,而不是全局一致性。
- SLAM 的基础:VO 通常作为 SLAM 的基础模块,SLAM 在 VO 的基础上进行地图构建和闭环检测。
- 实时性能:由于 VO 不构建地图,也不做闭环检测,因此它更适合实时应用,虽然会牺牲一些全局精度。
VO 侧重于实时的局部一致性,适用于对环境的快速路径估算。而 SLAM 更加全面,不仅提供路径,还能构建环境的全局地图,并纠正漂移误差。可以把 VO 看成 SLAM 在进行闭环检测和全局优化之前的一个阶段。
 wechat
wechat alipay
alipay






